
本文是《》的系列博文。
许多网友们都对 Smart Framework 的异常处理机制抱有疑问,我想很有必要补充一篇博文,描述一下为何我要采用基于“错误代码”的解决方案,来替换原有 Java 异常处理方案。
先来回顾一下 Java 异常处理的来龙去脉。
早在 JDK 1.0 的时候,Sun 公司的牛逼人物 Josh Bloch 就写了一个 Throwable 类,它是所有异常的父类,包括两个子类:Error 与 Exception。
Error 表示程序运行错误,立马需停止执行。此时没必要使用 try-catch 结构来捕获 Error 错误,因为 catch 块根本就就进不去。
Exception 就不用解释了,我们太熟悉了,可以用 try-catch 结构来捕获异常。
当 Exception 出世后,程序可以这样写了:
先定义一个接口:
public interface Greeting { void sayHello(String name) throws Exception;} 在方法声明处定义了所抛出异常的类型,可以抛出多个异常,每个异常类需要用逗号隔开。
假设我们写一个实现类,在其中判断参数是否为 null,若为 null,就抛出 Exception。
public class GreetingImpl implements Greeting { @Override public void sayHello(String name) throws Exception { if (name == null) { throw new Exception("The name is null."); } System.out.println("Hello! " + name); }} 在 Exception 的构造方法中传入异常消息。如果抛出了异常,后面的 System.out.println() 语句是绝对不会执行的。那下一步执行什么呢?或者说,当前线程跑到哪里去了呢?跑到调用这个方法的地方了,请看如下代码:
public class Client { public static void main(String[] args) { Greeting greeting = new GreetingImpl(); try { greeting.sayHello(null); } catch (Exception e) { System.out.println("Error! Message: " + e.getMessage()); } }} 通过一个 try-catch 语句,捕获了 Exception 异常,线程进入了 catch 块中,使用控制台输出了异常信息。
也就是说,异常是从下往上抛的。打个比方吧,当项目组里出了一个小问题,Leader 看了一下,自己管不了,就向上抛给 Manager 去处理,Manager 看了一下发现自己也管不了,于是就继续往上抛,抛给了 Boss,此时,Boss 再也不能向上抛了,只有自己解决(当然有这样的 Boss 那真是一件幸福的事了)。在这个例子中,最终就交给 Client 类来处理了,看看输出的异常信息就明白了。
OK,这就是 Java 异常的基本用法。
需要注意的是,凡是在方法签名中 throws 了 Exception 或其子类,必须在调用的时候使用 try-catch,这是 Java 的语言规范(可不是我规定的)。这就是传说中的“Checked Exception(受检异常)”。
如果在项目开发中经常使用受检异常,不见得是一件好事。举个例子,某方法定义可抛出 A 受检异常,这个方法已经被许多地方调用了,现在突然增加了 B 受检异常,那么也就意味着,所有调用该方法的地方都会报错,除非 catch 的是 Exception 或 Throwable。这种改变受检异常的方式需要谨慎使用。
与受检异常对应就是 Unchecked Exception(非受检异常)了,它有什么特点呢?
不妨先来举个非受检异常的例子,最经典的就是 RuntimeException 了,它是 Sun 公司年轻的程序员屌丝 Frank Yellin 的杰作。他提出,可以将方法签名无需显式地 throws 某个异常,而是在方法体中通过 throw 语句抛出 RuntimeException。看起来就像这样:
接口不再定义受检异常:
public interface Greeting { void sayHello(String name);} 在实现类的具体方法执行的时候抛出 RuntimeException:
public class GreetingImpl implements Greeting { @Override public void sayHello(String name) { if (name == null) { throw new RuntimeException("The name is null."); } System.out.println("Hello! " + name); }} 这样处理以后,Client 再也不需要 try-catch 了:
public class Client { public static void main(String[] args) { Greeting greeting = new GreetingImpl(); greeting.sayHello(null); }} 代码确实精简了不少,脱掉了恶心的 try-catch 这件衣服,但是这样再也不能捕获异常了,因为非受检异常是隐性的,除非在项目中约定,这个方法可能会抛出某某异常,然后调用的人还是用 try-catch 去捕获这些异常。总之,非受检异常是代码干净了,但需要增加文档约束,所以就必须写一大堆的 JavaDoc 了。
public class Client { public static void main(String[] args) { Greeting greeting = new GreetingImpl(); try { greeting.sayHello(null); } catch (RuntimeException e) { System.out.println("Error! Message: " + e.getMessage()); } }} 看来,还是脱不了那件衣服啊!
既然脱不掉,就多买几件好看的衣服吧。于是,后面就有了 IOException、FileNotFoundExceptoin、NullPointerException 等等这些异常类了。
用一张图来表达这个异常结构吧:
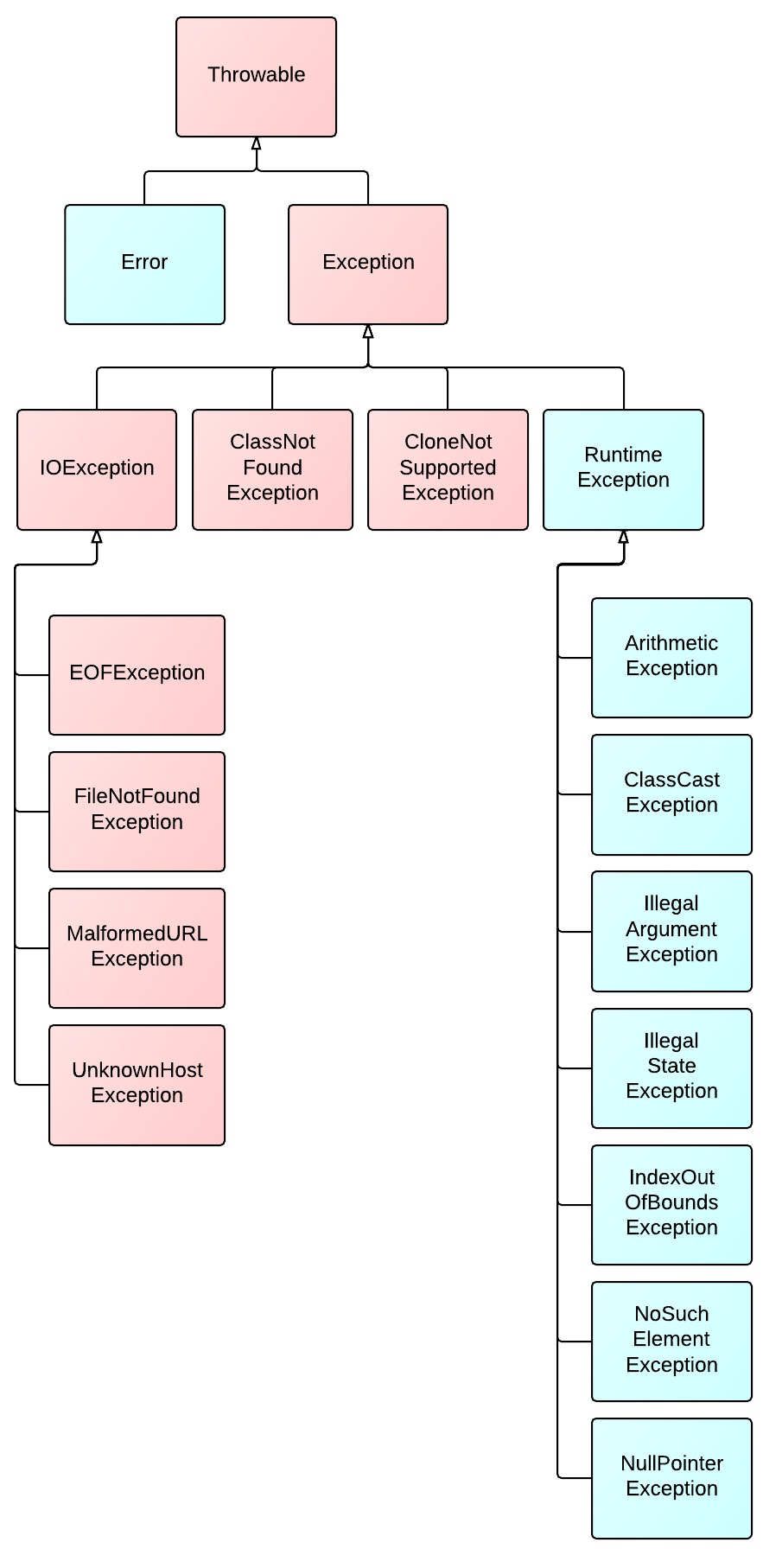
上图清晰地表明了,红色的是受检异常,蓝色的是非受检异常。
当然这些都是 JDK 给我们提供的,我们可以随时拿来使用,但情况远远没有那么理想。有些情况下,我们发现这些异常根本难以表达业务的具体含义,于是我们可以通过继承的方式来自定义异常,或者说扩展异常。看起来是这样的:
public class ParameterNullException extends RuntimeException { public ParameterNullException() { } public ParameterNullException(String message) { super(message); } public ParameterNullException(String message, Throwable cause) { super(message, cause); } public ParameterNullException(Throwable cause) { super(cause); }} 上面自定义了一个非受检异常 ParameterNullException(表示当参数为空时的异常),因为它直接继承了 RuntimeException。也就是说,这个异常可以隐式抛出,无需定义在方法签名上。看起来和使用 RuntimeException 差不多:
public class GreetingImpl implements Greeting { @Override public void sayHello(String name) { if (name == null) { throw new ParameterNullException("The name is null."); } System.out.println("Hello! " + name); }} 没错!只是改了一个名字,这样代码可读性确实上升了不少,至少可以做到望名生意了。
有了这个法宝以后,在 Java 项目中大量出现自定义异常,管理起来非常不便,而且有可能多个自定义异常类只是名字不同而已,意义却是完全相同的。
能否有更好的方法来改进异常处理行为呢?即需要保证有异常中止的功能,又需要保证有具体的业务意义,还需要保证代码可读性良好。
于是,我借鉴了 C/C++ 中的“错误代码”编程风格,现在是这样处理异常的:
public class GreetingImpl implements Greeting { @Override public int sayHello(String name) { if (name == null) { return 1; // Error: The name is null. } System.out.println("Hello! " + name); return 0; // Success }} 方法签名中无需声明任何受检异常,也无需在方法体中抛出非受检异常,只需提供方法返回值(假设为 int 类型,当然也可以为 String 类型),当返回 0 时,表示操作成功;当非 0 时,表示操作失败。对于非零的情况,可以自由定义错误代码,比如:1 表示参数为空,2 表示...,3 表示...。这些返回值就是错误代码。
在 Client 中是这样进行错误处理的:
public class Client { public static void main(String[] args) { Greeting greeting = new GreetingImpl(); int result = greeting.sayHello(null); if (result == 1) { System.out.println("Error! Code: " + result); } }} 没有了 try-catch,代码精简了。与受检异常完全不同,若方法中变更了错误代码,对调用方没有任何影响。此方案与非受检异常相似,同样需要给出一定的契约或者说是规范,让调用者知道该方法具体会返回多少种错误情况。于此不同的是,可以直接将这个错误代码返回到前端,通过 JS 来获取错误代码,从而给出相应的错误提示信息。在这一点上,似乎比非受检异常要强大一些。为了提高可读性与防止手误,可以将常用的返回值定义为常量。
细心的读者肯定会发现一个问题,如果方法本身就需要返回值,而这里的错误代码却充当了返回值,一个方法可以返回多个值吗?
可以的。那就是将返回值封装成 JavaBean 的样子,如下:
public class Result extends BaseBean { private boolean success = true; private int error = 0; private Object data = null; public Result(boolean success) { this.success = success; } public Result data(Object data) { this.data = data; return this; } public Result error(int error) { this.error = error; return this; }...} 将方法的返回值统一为 Result 对象,该对象包括三个属性: - success:操作是否成功(默认为 true,表示成功)
- error:错误代码(默认为 0,表示没有错误)
- data:真正的返回值(默认为 null,表示没有返回值)
此外,还通过链式调用进行传递这些属性,例如:
@Beanpublic class ProductAction extends BaseAction {... @Request("get:/product/{id}") public Result getProductById(long productId) { if (productId == 0) { return new Result(false).error(ERROR_PARAM); } Product product = productService.getProduct(productId); if (product != null) { return new Result(true).data(product); } else { return new Result(false).error(ERROR_DATA); } }... 以上是 Action 的写法,可以 if 语句检测方法参数是否有效,也可以检测 Service 方法返回值是否有效,通过链式操作来创建 Result 对象,并为其属性赋值。
代码可读性增强了,程序员可将更多的精力放在业务流程上,而并非那些 try-catch 上。
期待您的宝贵建议!如果对您有帮助,请顶起来吧!谢谢!